Characteristic-preserving Latent Space for Unpaired Cross-domain Translation of 3D Point Clouds
Introduction
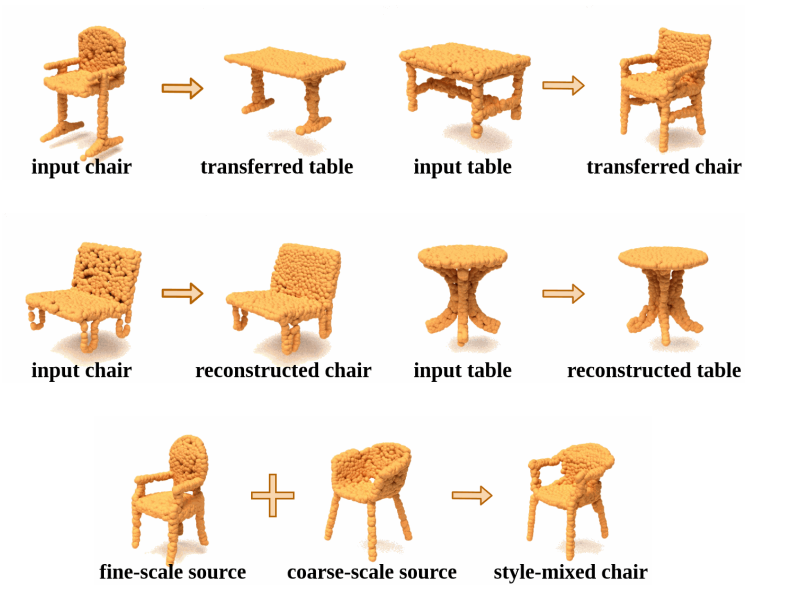
Our task is unpaired shape-to-shape translation across domains for 3D point clouds. Inspired by the design of LOGAN [61], we established an autoencoder and multiple translators that can encode 3D point clouds and process latent codes in common latent space, respectively. However, we found that the shape characteristics and details may not always be preserved after translation. We think shape characteristics of an object include its height or width, the number of branches of a joint, the contour curvature or thickness of a certain component, etc. Shape details include bulges or holes on the surface of a component, thin structure (such as bars, rungs, slats) between main components, etc. Those compelled us to consider how to retain the shape characteristics and model details of the transferred results. Taking the first row of Fig.1 as an example, we expect that the source characteristics, such as trestle feet (inverted Tshape legs) of the left input chair and the side and cross stretchers (horizontal bars) between the legs of the right input table, can be transferred to their counterparts in the target domains. To accomplish the challenging goal, we assumed and formulated the shape characteristics in latent space, and we proposed a novel characteristic-preserving loss (cp loss) to enforce the invariance of the characteristic features transferred across domains. Besides, a center loss is applied to making transferred latent codes close to the the target domain center. While we involved these two cross-domain losses into training, our transferred results keep the shape characteristics from the source as well as exhibit the typical features of the target domain. Fig. 2 illustrates the concept diagram of the proposed framework transferring sources (chairs in this example) to their corresponding targets (tables in this example) through our latent space.
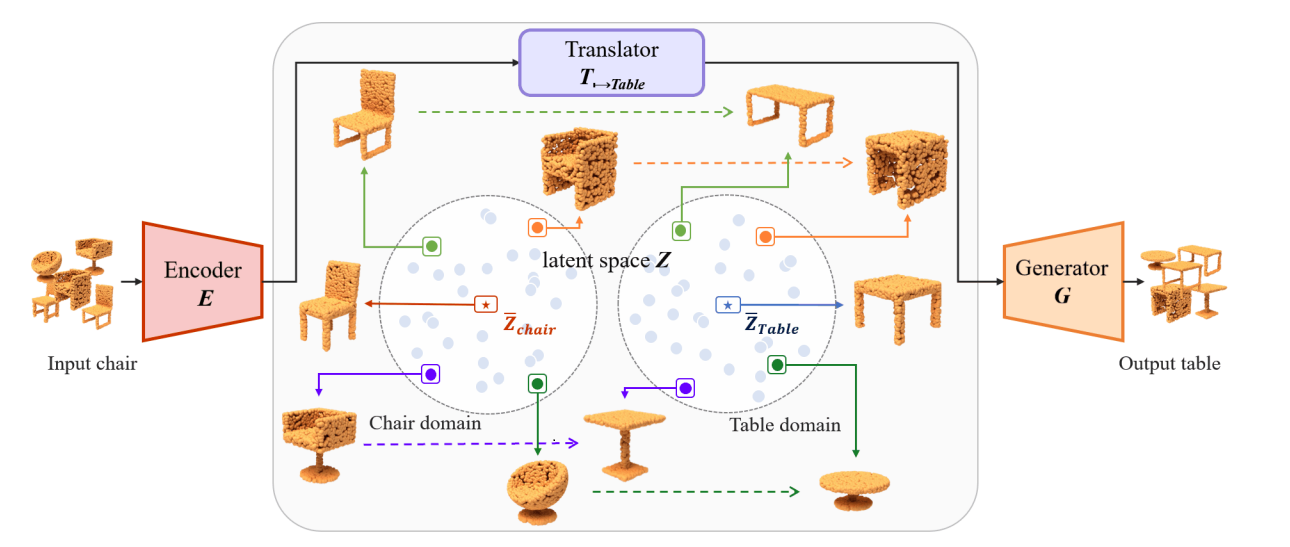
Fig. 2: Conceptual diagram of the proposed framework to transfer input chairs to their corresponding tables with similar
characteristics through the shape-aware latent space, which are formulated with our novel loss functions.
Experiments
Comparison with State-of-the-art Unpaired Translation Frameworks
As a pioneer work about general-purpose cross-domain transformation on point clouds, LOGAN [61] generated impressive results. UNIST [4] improves the translation by applying neural implicit functions as latent representation. It also samples point clouds for comparison. We reproduced these two state-of-the-art systems by their official codes. Fig. 13 compares our results with results of LOGAN and UNIST.
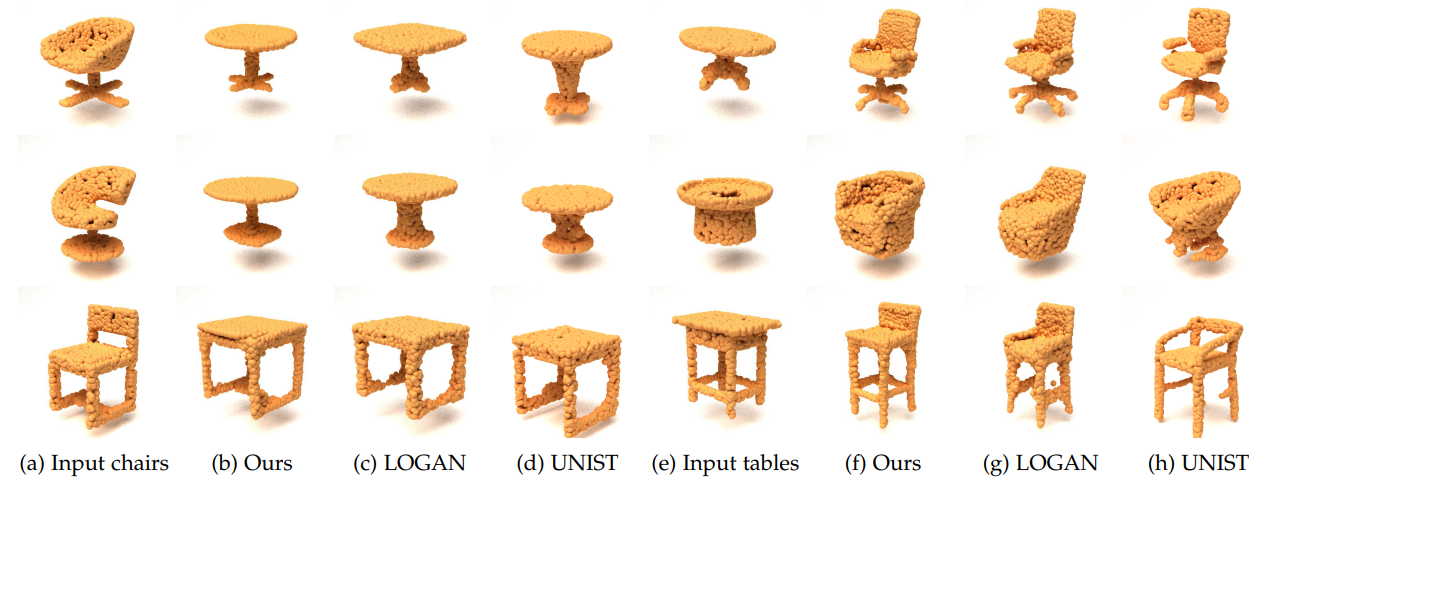
Fig. 13: Comparison of our transfer results with results generated by LOGAN [61] and UNIST [4]. (a) Input chairs. (b)
Our chair-to-table transferred results from (a). (c) The chair-to-table transferred results from (a) by LOGAN. (d) The chairto-table transferred results from (a) by UNIST. (e) Input tables. (f) Our table-to-chair transferred results from (e). (g) The
table-to-chair transferred results from (e) by LOGAN. (h) The table-to-chair transferred results from (e) by UNIST.
To quantitatively assess the translation performance, we conducted comparison on Paired Arm-and-armless Chairs test dataset. Ours (proposed trans.), UNIST, and LOGAN were trained with the original armchair and armless chair data from ShapeNet in an unpaired fashion. We applied the source codes and training parameters provided by the authors of these two compared methods for training. Since the output of UNIST is not on the original scale and pose of ShapeNet models, we normalized their translated results so that they can be compared with the results of LOGAN and ours. As shown in Table 4, the Arm→Armless translated shapes predicted by our proposed method are more accurate compared to those of LOGAN and UNIST in terms of both CD and EMD. For Armless→Arm translation, our results also outperform that of LOGAN, but we cannot perform UNIST on Armless→Arm data. That is because UNIST samples voxel models at three levels of resolution and stores the information in specific files. In the Arm→Armless translation, the volumetric armchairs for test inputs are provided by UNIST, and its output can be turned into point clouds. However, in the Armless→Arm translation, the input armless chairs are newly crafted in our Paired Arm-and-armless Chairs test dataset. They are in the form of point clouds and do not exist in the volumetric files provided by UNIST. We consider the advantages of our method result from two points. First, our encoder and decoder can record delicate structure, and second, the proposed loss functions guide the framework to keep characteristics beyond the mean (typical shape of a domain) during translation
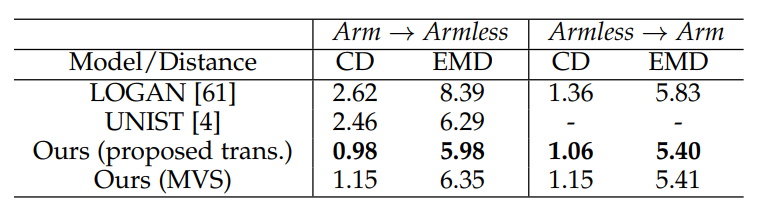
TABLE 4: Comparison of the proposed translation and
shifting framework with LOGAN [61] and UNIST [4]. LOGAN, UNIST, and Ours (proposed trans.) were trained
on arm-and-armless chair unpaired data from ShapeNet
and conducted translations. Ours (MVS) were trained on
chair and table unpaired data, and shifted shapes between
arm and armless properties. All these models were tested
on the Paired Arm-and-armless Chairs dataset. The reported
CD (chamfer distance) scores are multiplied by 103
and
EMD (earth mover’s distance) scores are multiplied by 102
.
(Armless→Arm of UNIST cannot be conducted due to lack
of armless-chair volumetric input.)
Our Paired Arm-and-armless Chairs Dataset
Paired Arm-and-armless Chairs Dataset
Based on the armchair and armless chair data
picked by [61] from ShapeNet Core [3], we extracted thirty
armchair models in various shapes with distinct armrests,
and we manually removed their armrest parts by a 3D point
editing tool. These manually trimmed chairs are unseen in
the original armless chair data, and they were upsampled
to 2048 points. We called this test dataset Paired Arm-andarmless Chairs.
We can see the figure below that these manually crafted armless version can become the pseudo ground
truth.

Fig. Examples of arm chairs and their armless chair counterparts, which are manually crafted. Currently, there are 30 pairs of arm- and armless-chairs in the test dataset.
download:
Paired Arm-and-armless Chairs Dataset
Our Code
Please visit this github page for more thorough implementation of our work: Github link
Publication
Jia-Wen Zheng, Jhen-Yung Hsu, Chih-Chia Li, I-Chen Lin*, "Characteristic-preserving Latent Space for Unpaired Cross-domain Translation of 3D Point Clouds," IEEE Transactions on Visualization and Computer Graphics, 30(8): 5212-5226, Aug. 2024. (SCI, EI)
Paper:
preprint_version (about 25.3MB), published version (link to the IEEE digital library)
Supplementary file:
Supplementary file (pdf, about 18.1MB)
BibTex
@ARTICLE{ZhengTVCG24,
author={Zheng, Jia-Wen and Hsu, Jhen-Yung and Li, Chih-Chia and Lin, I-Chen},
journal={IEEE Transactions on Visualization and Computer Graphics},
title={Characteristic-Preserving Latent Space for Unpaired Cross-Domain Translation of 3D Point Clouds},
year={2024},
volume={30},
number={8},
pages={5212-5226},
doi={10.1109/TVCG.2023.3287923}
}